引自:
一、风格迁移简介
风格迁移(Style Transfer)是深度学习众多应用中非常有趣的一种,如图,我们可以使用这种方法把一张图片的风格“迁移”到另一张图片上:
 然而,原始的风格迁移(论文地址:)的速度是非常慢的。在GPU上,生成一张图片都需要10分钟左右,而如果只使用CPU而不使用GPU运行程序,甚至需要几个小时。这个时间还会随着图片尺寸的增大而迅速增大。
然而,原始的风格迁移(论文地址:)的速度是非常慢的。在GPU上,生成一张图片都需要10分钟左右,而如果只使用CPU而不使用GPU运行程序,甚至需要几个小时。这个时间还会随着图片尺寸的增大而迅速增大。
这其中的原因在于,在原始的风格迁移过程中,把生成图片的过程当做一个“训练”的过程。每生成一张图片,都相当于要训练一次模型,这中间可能会迭代几百几千次。如果你了解过一点机器学习的知识,就会知道,从头训练一个模型要比执行一个已经训练好的模型要费时太多。而这也正是原始的风格迁移速度缓慢的原因。
二、快速风格迁移简介
那有没有一种方法,可以不把生成图片当做一个“训练”的过程,而当成一个“执行”的过程呢?答案是肯定的。这就这篇快速风格迁移(fast neural style transfer):
快速风格迁移的网络结构包含两个部分。一个是“生成网络”(原文中为Transformation Network),一个是“损失网络”(Loss Network)。生成网络接收一个图片当做输入,然后输出也是一张图片(即风格迁移后的结果)。如下图,左侧是生成网络,右侧为损失网络:
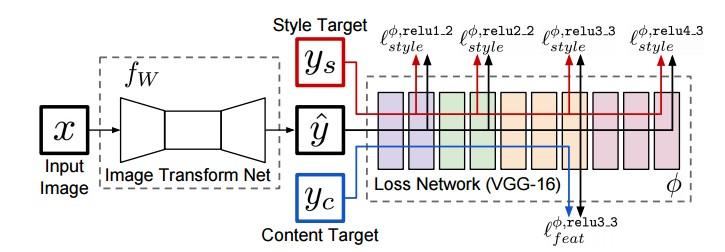
训练阶段:训练的目标是让生成网络可以有效生成图片。目标由损失网络定义。
具体过程:选定一张风格图片。训练过程中,将数据集中的图片输入网络,生成网络生成结果图片y,损失网络提取图像的特征图,将生成图片y分别与目标风格图片ys和目标输入图片(内容图片)yc做损失计算,根据损失值来调整生成网络的权值,通过最小化损失值来达到目标效果。
执行阶段:给定一张图片,将其输入生成网络,输出这张图片风格迁移后的结果。
我们可以发现,在模型的“执行”阶段我们就可以完成风格图片的生成。因此生成一张图片的速度非常块,在GPU上一般小于1秒,在CPU上运行也只需要几秒的时间。
生成网络
对于生成网络,本质上是一个卷积神经网络,这里的生成网络是一个深度残差网络,不用任何的池化层,取而代之的是用步幅卷积或微步幅卷积做网络内的上采样或者下采样。这里的神经网络有五个残差块组成。除了最末的输出层以外,所有的非残差卷积层都跟着一个空间性的instance-normalization,和RELU的非线性层,instance-normalization正则化是用来防止过拟合的。最末层使用一个缩放的Tanh来确保输出图像的像素在[0,255]之间。除开第一个和最后一个层用9x9的卷积核(kernel),其他所有卷积层都用3x3的卷积核。
损失网络
损失网络φ是能定义一个内容损失(content loss)和一个风格损失(style loss),分别衡量内容和风格上的差距。对于每一张输入的图片x我们有一个内容目标yc一个风格目标ys,对于风格转换,内容目标yc是输入图像x,输出图像y,应该把风格ys结合到内容x=yc上。系统为每一个目标风格训练一个网络。
为了明确逐像素损失函数的缺点,并确保所用到的损失函数能更好的衡量图片感知及语义上的差距,需要使用一个预先训练好用于图像分类的CNN,这个CNN已经学会感知和语义信息编码,这正是图像风格转换系统的损失函数中需要做的。所以使用了一个预训练好用于图像分类的网络φ,来定义系统的损失函数。之后使用同样是深度卷积网络的损失函数来训练我们的深度卷积转换网络。
这里的损失网络虽然也是卷积神经网络(CNN),但是参数不做更新,只用来做内容损失和风格损失的计算,训练更新的是前面的生成网络的权值参数。所以从整个网络结构上来看输入图像通过生成网络得到转换的图像,然后计算对应的损失,整个网络通过最小化这个损失去不断更新前面的生成网络权值。
感知损失
对于求损失的过程,不用逐像素求差构造损失函数,转而使用感知损失函数,从预训练好的损失网络中提取高级特征。在训练的过程中,感知损失函数比逐像素损失函数更适合用来衡量图像之间的相似程度。
(1)内容损失
上面提到的论文中设计了两个感知损失函数,用来衡量两张图片之间高级的感知及语义差别。内容的损失计算用VGG计算来高级特征(内容)表示,因为VGG模型本来是用于图像分类的,所以一个训练好的VGG模型可以有效的提取图像的高级特征(内容)。计算的公式如下:

找到一个图像 y使较低的层的特征损失最小,往往能产生在视觉上和y不太能区分的图像,如果用高层来重建,内容和全局结构会被保留,但是颜色纹理和精确的形状不复存在。用一个特征损失来训练我们的图像转换网络能让输出非常接近目标图像y,但并不是让他们做到完全的匹配
(2)风格损失
内容损失惩罚了输出的图像(当它偏离了目标y时),所以同样的,我们也希望对输出的图像去惩罚风格上的偏离:颜色,纹理,共同的模式,等方面。为了达成这样的效果,一些研究人员等人提出了一种风格重建的损失函数:让φj(x)代表网络φ的第j层,输入是x。特征图谱的形状就是Cj x Hj x Wj、定义矩阵Gj(x)为Cj x Cj矩阵(特征矩阵)其中的元素来自于:

如果把φj(x)理解成一个Cj维度的特征,每个特征的尺寸是Hj x Wj,那么上式左边Gj(x)就是与Cj维的非中心的协方差成比例。每一个网格位置都可以当做一个独立的样本。这因此能抓住是哪个特征能带动其他的信息。梯度矩阵可以很高效的计算,通过调整φj(x)的形状为一个矩阵ψ,形状为Cj x HjWj,然后Gj(x)就是ψψT/CjHjWj。风格重建的损失是定义的很好的,甚至当输出和目标有不同的尺寸是,因为有了梯度矩阵,所以两者会被调整到相同的形状。
三、快速风格迁移的Tensorflow实现
话不多说,直接上我的代码的Github地址:
还有变换效果如下。
原始图片:
 风格迁移后的图片:
风格迁移后的图片:



 以上图片在GPU(Titan Black)下生成约需要0.8s,CPU(i7-6850K)下生成用时约2.9s。
以上图片在GPU(Titan Black)下生成约需要0.8s,CPU(i7-6850K)下生成用时约2.9s。
关于快速风格迁移,其实之前在Github上已经有了Tensorflow的两个实现:
但是第一个项目只提供了几个训练好的模型,没有提供训练的代码,也没有提供具体的网络结构。所以实际用处不大。
而第二个模型做了完整的实现,可以进行模型的训练,但是训练出来的效果不是很好,在作者中,给出了一个范例,可以看到生成的图片有很多噪声点:

我的项目就是在的基础上做了很多修改和调整。
四、一些实现细节
1、与Tensorflow Slim结合
在原来的实现中,作者使用了VGG19模型当做损失网络。而在原始的论文中,使用的是VGG16。为了保持一致性,我使用了Tensorflow Slim(地址:)对损失网络重新进行了包装。
Slim是Tensorflow的一个扩展库,提供了很多与图像分类有关的函数,已经很多已经训练好的模型(如VGG、Inception系列以及ResNet系列)。
下图是Slim支持的模型:
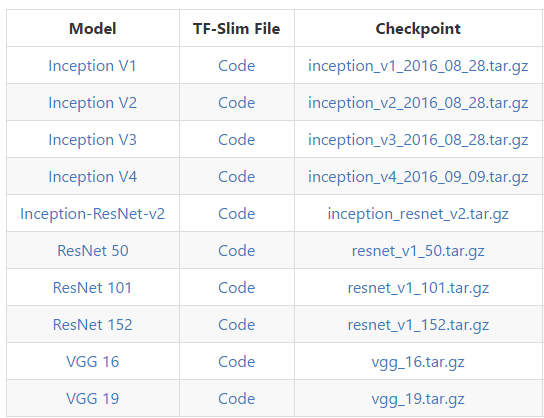 使用Slim替换掉原先的网络之后,在损失函数中,我们不仅可以使用VGG16,也可以方便地使用VGG19、ResNet等其他网络结构。具体的实现请参考源码。
使用Slim替换掉原先的网络之后,在损失函数中,我们不仅可以使用VGG16,也可以方便地使用VGG19、ResNet等其他网络结构。具体的实现请参考源码。
2、改进转置卷积的两个Trick
原先我们需要使用网络生成图像的时候,一般都是采用转置卷积直接对图像进行上采样。
指出了转置卷积的一些问题,认为转置卷积由于不合理的重合,使得生成的图片总是有“棋盘状的噪声点”,它提出使用先将图片放大,再做卷积的方式来代替转置卷积做上采样,可以提高生成图片的质量,下图为两种方法的对比:

对应的Tensorflow的实现:
以上为第一个Trick。
第二个Trick是文章 中提到的,用 Instance Normalization来代替通常的Batch Normalization,可以改善风格迁移的质量。
3、注意使用Optimizer和Saver
这是关于Tensorflow实现的一个小细节。
在Tensorflow中,Optimizer和Saver是默认去训练、保存模型中的所有变量的。但在这个项目中,整个网络分为生成网络和损失网络两部分。我们的目标是训练好生成网络,因此只需要去训练、保存生成网络中的变量。在构造Optimizer和Saver的时候,要注意只传入生成网络中的变量。
找出需要训练的变量,传递给Optimizer:
五、总结
总之是做了一个还算挺有趣的项目。代码不是特别多,如果只是用训练好的模型生成图片的话,使用CPU也可以在几秒内运行出结果,不需要去搭建GPU环境。建议有兴趣的同学可以自己玩一下。(再贴下地址吧:)
关于训练,其实也有一段比较坎(dan)坷(teng)的调参经历,下次有时间再分享一下,今天就先写到这儿。谢谢大家!